Interviews suck. And determining a candidates SQL skill is hard to do, especially in a short amount of time. Here’s a guide to make SQL Interviews suck less, whether your are the candidate or the interviewer.
Hopefully, by the end of this post, you’ll have a good understanding of both sides of the SQL Interview, what to look for in a candidate, or what you should know as a candidate. Remember that the interviewer is trying to find reasons not to hire the candidate. Preparation is key.
The basics
Here are some database basics. Some might want to skip this section and go straight to the questions, but I have included this for completeness. These are good questions to ask on a phone screen to gauge the candidate’s exposer to relational databases.
What is a database?
A database is a tool for storing and retrieving data with the intent to make it easy to query and analyze, while also providing utility for redundancy, fault tolerance, and ACIDity. There are now many types of databases, which each focused on improving different pain points, but still the most common is the traditional relational database (or RDMS), and that is what we’ll be focusing on.
What is SQL?
SQL stands for Structured Query Language. It is used to retrieve and analyze data in a database. It is a declarative language, so its syntax doesn’t resemble imperative or Object Oriented languages like C, Java, or C#. However, it is extremely powerful and performant, if you know how to write it correctly. It’s important to note that there are many ways to write SQL incorrectly, and you usually only learn the correct ways through experience.
What are tables?
Data in database is primarily located in tables. Tables are composed of columns and rows, where columns define the structure of the data, and the rows contain the record of the data itself. Relations exist between tables to correlate data of different structure.
What are keys?
Keys are the columns in a table that are used to relate data. A candidate key is defined to bring uniqueness to a record, or row. A table may have multiple candidate keys, but one is usually designated to be the primary key. It could be generated (Usually a unique autoincrementing integer), something naturally unique, or compound (also known as composite) which is when multiple columns combine to form a unique key). Tables can also contain references to another table’s key, which is known as a foreign key.
What is a schema?
A schema defines how tables in a database are related. A proper schema will map all of its keys and foreign keys, so that users of the schema know exactly how the data is related.
Some databases, like Postgres or SQL Server, also require that all tables are grouped in schemas. Here, the schema also acts as a namespace (or tablespace (TODO?)) for tables.
There are two primary ways to go about correctly defining a schema. The first is for operational or transactional databases (OLTP), where the schema should be normalized, and only denormalized if absolutely necessary for performance. The other is for analytical databases (OLAP), where a Star Schema or Snowflake Schema should be used instead.
What are views?
Views can be thought of as predefined queries, which give you a view into the table or tables they pull data from. They can be used to make browsing the data more human friendly, perform calculations for analysis, or provide a layer of abstraction between the tables and queries, to help ease the impact of schema changes affecting dependent code or processes.
By default, views only calculate data on demand. This has its advantages and disadvantages. For example, it means that there is no additional data stored on the server, but all the joins and calculations have to be computed each time the query is ran. Materialized views, however, provide a way to the data used by the views on disk.
What are indexes (or indices)
Indexes are what make queries, filters, and joins performant. Under the hood, an index is a data structure (often a btree) that relates the data contained in a column or columns, to the location of that row on the disk. This means that a query that utilizes an index will not have to scan through every single row contained in a table to gather the result set, but rather use the index to find the row it needs on disk, then read the record.
There are a few types of indexes. A clustered index represents a index where the indexed data matches the order of the data stored on disk. A table can only have one clustered index. Indexes can also be compound, meaning that multiple columns are defined in the index. But, for example, an index defined as (Name, DateOfBirth) will not improve the performance of a query that filter on DateOfBirth but not Name. Alternatively, you can define an index on Name and DateOfBirth individually.
Having too many indexes has its drawbacks. Indexes consume space on disk, and any time the data is added, updated, or deleted, any affected indexes must be altered as well, adding overhead to the operation. It is a best practice to only define the indexes that you will be using.
What are constraints?
Constraints are rules defined on tables that must be met when the data is modified in any way. Some examples are be uniqueness, not null constraints on a column, or validation rules. Constraints are very flexible and go a long way in ensuring data quality and integrity.
What are functions?
Similar to functions in mathematics, SQL functions are methods that optionally take input and return some output. They are used in SQL statements to compute, generate, and aggregate values. TODO: EXPAND?
What are stored procedures?
Stored procedures can be thought of as scripts stored in the database that accept input parameters, and can do just about anything, including return data. They are more flexible than functions, but can be used in less situations. TODO:Expand?
What are triggers?
Triggers contain code that automatically runs when an event happens. For example, a trigger on a User table might write a record to the Audit table when the password column is updated.
Interview questions
I’ve been a fan of Jitbit’s SQL Interview Questions and started using them when interviewing candidates, with good results. The schema is easy to grok, the questions are simple, but they test a wide array of SQL knowledge. My questions aren’t all 100% matches from Jibit’s, but most are close. Jitbit’s site didn’t have any output requirements. I think it helps to define the data we’re looking for. Thanks to Jitbit for sharing these.
Although a developer who has a solid SQL background should be able to whiteboard these, I think it’s best to let the candidate work with actual data in a database when possible. Preferably using the tools they are most comfortable with. This will allow them to run the queries, see the results, and spot any mistakes they might have, instead of needing to guide them to their issues on a whiteboard. Though, you should definitely guide them if they are using a whiteboard.
On that note, I create a script to create and populate the data. For those familiar with The Office, please excuse the illogicalness of the data. It is designed to show results with edge cases for each question.
create table Employee (
EmployeeId int not null,
DepartmentId int,
BossId int,
Name nvarchar(50) not null,
Salary int
);
create table Department (
DepartmentId int not null,
Name nvarchar(50) not null
);
insert into Department (DepartmentId, Name)
values
(1, 'Management'),
(2, 'Sales'),
(3, 'Accounting'),
(4, 'Human Resources'),
(5, 'Compliance'),
(6, 'Office Management');
insert into Employee ( EmployeeId, DepartmentId, BossId, Name, Salary)
values
(9999, 1, null, 'Robert California', 500000),
(1, 1, 9999, 'Michael Scott', 100000),
(2, 2, 1, 'Dwight Scrute', 115000),
(3, 2, 1, 'Jim Halpert', 95000),
(4, 6, 1, 'Pam Beasley', 50000),
(5, null, null, 'Creed Bratton', 85000),
(6, null, 1, 'Ryan Howard', 30000),
(7, 3, 1, 'Angela Martin', 80000),
(8, 3, 7, 'Oscar Martinez', 75000),
(9, 3, 7, 'Kevin Malone', 90000),
(10, 4, 9999, 'Toby Flenderson', 60000),
(11, 2, 1, 'Stanley Hudson', 95000),
(12, 1, 9999, 'Daryll Philbin', 80000),
(13, 4, 9999, 'Holly Flax', 60000);
And here is the schema:
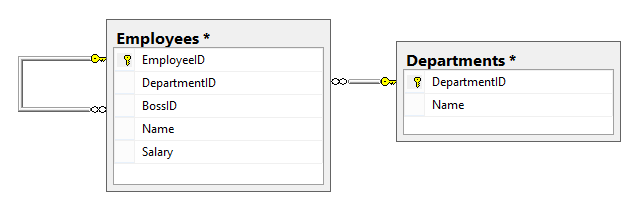
Let’s look at the questions. And remember: With SQL, there is always more than one way to arrive at the correct answer, but I’m going show what solutions I find are the cleanest.
1. List all employees who have a bigger salary than their boss.
Output should include EmployeeName, EmployeeSalary, BossName, BossSalary.
The result set should be
| Employee Name | Employee Salary | Boss Name | Boss Salary |
|---|---|---|---|
| Dwight Schrute | 115,000 | Michael Scott | 100,000 |
| Kevin Malone | 90,000 | Angela Martin | 80,000 |
This is not a hard query, but it’s a good first question. The most common mistake here is swapping the employee and boss tables in the join condition. It’s natural to want to write ‘boss.BossId = employee.EmployeeId’, but that is not how the relation works. In fact, most people I’ve interviewed make this mistake the first time through. However, it’s not a big deal if they can quickly identify and correct the issue on their own.
Here’s my answer:
select
e.name as EmployeeName,
e.Salary as EmployeeSalary,
b.Name as BossName,
b.Salary as BossSalary
from
Employee e
join Employee b
on b.EmployeeId = e.BossId
where
e.Salary > b.Salary;
2. List all departments that have less than 3 employees in it.
Output should include DepartmentName, NumberOfEmployees.
This one is straightforward. The candidate should handle zero employee departments without guidance here.
| Department Name | Employee Count |
|---|---|
| Compliance | 0 |
| Human Resources | 2 |
| Office Management | 1 |
And here is how I would write it:
select
d.DepartmentId,
d.Name as DepartmentName,
count(e.EmployeeId) as EmployeeCount
from
Department d
left join Employee e
on e.DepartmentId = d.DepartmentId
group by
d.DepartmentId,
d.Name
having count(e.EmployeeId) < 3;
3. List all departments with the total salary of the department.
Output should include DepartmentName, TotalSalary.
Here’s another one that focuses on aggregates. It’s still fairly straightforward.
Result set:
| Name | Total Salary |
|---|---|
| Accounting | 245,000 |
| Compliance | 0 |
| Human Resources | 120,000 |
| Management | 680,000 |
| Office Management | 50,000 |
| Sales | 305,000 |
Note the 0 in the result set. A little bit of null handling will need to be done here. Knowing how to handle nulls in SQL is very important.
Here is the query:
select
d.Name,
coalesce(sum(e.Salary), 0) as TotalSalary
from
Department d
left join Employee e
on e.DepartmentId = d.DepartmentId
group by
d.Name;
4. List the employees with the highest salary in each department.
Output should include DeparmentName, EmployeeName, Employee Salary.
There are two things to look out for here - ties and empty departments. Don’t knock a candidate if their query doesn’t take these situations into account and you don’t advise them before they started writing the SQL. But, bonus points for candidates who ask for clarification here.
Here is what the results should be:
| Department Name | Employee Name | Employee Salary |
|---|---|---|
| Management | Robert California | 500,000 |
| Sales | Dwight Scrute | 115,000 |
| Accounting | Kevin Malone | 90,000 |
| Human Resources | Toby Flenderson | 60,000 |
| Human Resources | Holly Flax | 60,000 |
| Compliance | NULL | NULL |
| Office Management | Pam Beasley | 50,000 |
This question has many possible solutions, and I won’t really put one over another. Here a couple ways to solve it. All of these solutions show empty departments, with a comment on how to exclude them.
Using a ‘where not exists’ subquery:
select
d.Name as DepartmentName,
e.Name as EmployeeName,
e.Salary as EmployeeSalary
from
Department d
left join Employee e -- inner join here to remove empty departments
on e.DepartmentId = d.DepartmentId
where
not exists (
select 1
from Employee t
where
t.DepartmentId = e.DepartmentId
and t.Salary > e.Salary
);
Using a rank window function:
with ranked as (
select
d.Name as DepartmentName,
e.Name as EmployeeName,
e.Salary as EmployeeSalary,
rank() over(partition by d.DepartmentId order by e.Salary desc) Rank
from
Department d
left join Employee e -- inner join here to remove empty departments
on e.DepartmentId = d.DepartmentId
)
select *
from ranked
where Rank = 1;
Another option would be using a common table expression (with statement) to find the max salary for each department, by grouping by DepartmentId and Salary, then joining that back to the Employees table. It’s a bit more code than these other two solutions though.
5. Show the salary of each department as a percentage of the salary of all employees
Output should include the DepartmentName, TotalSalary, and PercentOfTotal. There should also be a row that shows the total salary of all employees.
This one is a bit more complex than all of the previous questions. If someone aces the rest, this question should be a good gauge of their experience with SQL.
For this result set, there are a few things to point out. There is a row for All Employees, which should show the total salary of every employee. There are also employees who aren’t assigned to any departments (Who knows what Creed and Ryan do?), but they should be in the result set. Last, we again need to handle departments with no employees.
Here are the results, with the percentages rounded to two decimal places:
| Department | Total Salary | % Of Total |
|---|---|---|
| All Employees | 1,515,000 | 100 |
| NULL | 115,000 | 7.59 |
| Accounting | 245,000 | 16.17 |
| Compliance | 0 | 0 |
| Human Resources | 120,000 | 7.92 |
| Management | 680,000 | 44.88 |
| Office Management | 50,000 | 3.30 |
| Sales | 305,000 | 20.13 |
Again, there are many ways to solve this one. This one will also vary based on the database used. Some of the syntax, for example, getting the cartesian product or casting a value, may be different.
Here is the SQL for SQL Server:
with salaryByDepartment as (
select
d.Name,
coalesce(sum(e.Salary), 0) as TotalSalary
from
Department d
full join Employee e
on e.DepartmentId = d.DepartmentId
group by d.Name
),
totalSalary as (
select sum(e.Salary) as TotalSalary
from Employee e
)
select
'All Employees' as Department,
ts.TotalSalary,
100 as PercentOfTotal
from totalSalary ts
union all
select
sbd.Name,
sbd.TotalSalary,
(cast(sbd.TotalSalary as float) / ts.TotalSalary) * 100
from
salaryByDepartment sbd
cross apply totalSalary ts;
There are a lot of little things here. Full joins, aggregates, null handling, type casting, unioning, and cross joining. If you give this question to a candidate, don’t worry if it takes a few iterations for them to get it right. Guiding them in the right direction will help as well. You may also accept a more simpler solution if your strict on time. For example, you can not worry about empty departments and including the total salary of all employees in the results set.
Final thoughts
I don’t think it is necessary do to all 5 questions, but you would want to do at least 2 or 3. In that case, tailor choose the difficulty of the questions to match the candidate’s skill level. The questions listed here are mostly ordered in ascending difficulty, with number 5 being a clear notch above the rest.
You want to judge the candidates on their problem-solving ability, not their knowledge of syntax and keywords. I always allow candidates to ask me questions as if I were Google. Syntax knowledge is fleeting if it’s not used often. The ability to understand and solve real problems is valuable. That’s what you need to be able to asses in candidates.